Impala 쿼리를 통해 정확하진 않더라도 대략적인 distinct한 모수를 추정하고 싶을 때 사용할 수 있는 함수가 있어 간단히 확인한겸 옮겨 적어본다. 보통 추정에서 많이 사용되는 하이퍼로그로그와 비슷한 기능을 IMPALA에서도 제공하고 있다. 물론 적은 리소스를 가지고 효율적으로 추정만 하기에 정확한 모수를 알고 싶은경우는 패스하도록 한다. 차이는 대략 1.9%정도 났다. (일반적으로 3%정도 차이가 난다고 생각하면 된다.)
최근 사이즈가 큰 대략 두 데이터 각각 2TB (2000GB) 정도의 데이터의 ID값들을 JOIN시켜 얼마나 일치하는지 확인하는 작업을 진행하였다. 간만에 들어온 Adhoc요청에 요구사항 파악이 먼저였고 "사이즈가 커봤자 스파크가 executor개수와 core개수 excetuor memory설정만 맞춰주면 잘 돌리면 되겠다."라고 생각했었다.
하지만 사이즈가 크다보니 실제 운영 클러스터에서 spark-shell에 접속해 command를 날리는건 클러스터의 실제 운영되는 작업에 영향을 줄 수 있기에 일정 부분의 데이터들을 떼와 로컬 Spark 모듈 프로젝트를 통해 원하는대로 파싱하고 조인해서 결과값이 나오는지 먼저 확인하였다.
두 데이터 각각 2TB들을 가공해 뽑아야 하는 조건은 15가지 정도 되었고 나는 해당 코드작업을 하고 jar파일로 말아 특정 리소스풀을 사용하는 조건과 스파크 설정값들을 알맞게 설정해 spark-submit을 실행할 예정이었다.
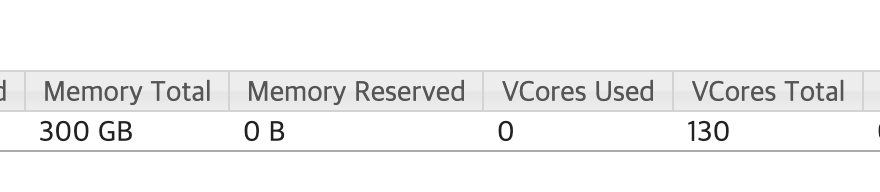
작업에 대해 설명하기 전에 클러스터 규모에 대해 간단히 언급하자면 실제 서비스를 운영하는 클러스터는 아니였고
Data Lake로 사용되는 데이터노드 5대로 이루어진 규모가 그렇게 크지 않은 클러스터였다.
가용 가능 최대 메모리는 300GB, VCore 개수는 130개 정도 규모
데이터 추출의 첫 번째 조건
특정 action을 했던 ID값들을 뽑아 distinct하고 counting하는 작업이었다.
물론 데이터사이즈가 크긴했지만 단순한 작업이였기에 그렇게 오래는 걸리지 않을거라고 예상했다 (20분 이내 예상)
실제 Spark-submit을 수행하였고 각 파일들을 읽어들여 카운팅 작업이 수행되는 것을 Spark에서 제공하는 Application UI을 통해 어떤 작업 현재 진행중인지 executor들을 잘 할당되어 일을 하고 있는지를 모니터링 하였다.
근데 이게 왠걸??? Couning을 하는 단계에서 실제 action이 발생했고 (Spark는 lazy연산이 기본) 시간이 너무 오래걸리는 걸 발견하였다...한 시간 이상이 지나도 끝나지 않은 것으로....기억한다.
따라서 이대로는 안되겠다 싶어 일단 요구사항들 중 한번에 같이 처리할 수 있는 그룹 세개로 나누고 기존 데이터를 가지고 처리할게 아니라 특정조건으로 filterling이 된 실제 필요한 데이터들만 가지고 작업을 해야겠다고 생각했다.
그래서 일단 원하는 조건으로 filterling을 한 후 해당 데이터들만 hdfs에 다시 적재했다.
실제 처리에 사용될 데이터 사이즈가 2~4G로 훅 줄었고 (다른 값들을 다 버리고 조건에 맞는 실제 ID값만 뽑아냈기 때문) 이제 돌리면 되겠다 하고 생각하고 돌렸다.
그런데...데이터 사이즈가 2~4G밖에 안되는 데이터들간 Join을 하고 Counting을 하는 작업이 무슨 20~30분이나 걸린단 말인가?....(1~3분 이내를 예상했음)
그래서 이전에 비슷한 상황에서 실제 데이터들의 파티션이 데이터 사이즈에 비해 너무 많이 나누어져 있어서 Spark가 구동되며 execution plan을 세울 때 많은 task들이 발생되어 성능이 떨어졌던 기억이 있어 필터링 한 데이터들의 파티션 개수를 세어 보았더니...
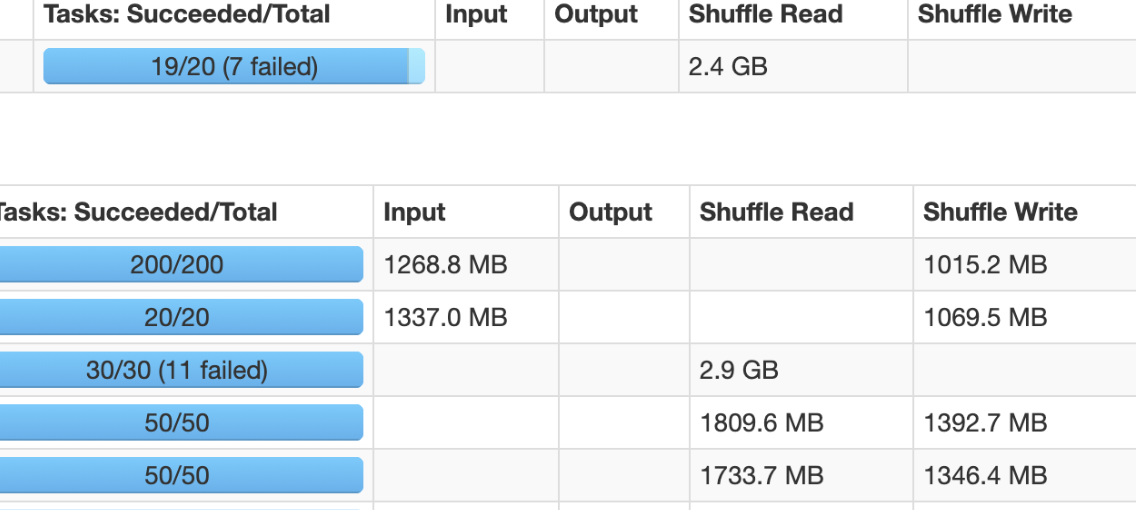
사이즈가 2.6G가 밖에 안되는 실제 사용될 데이터의 파일의 개수가....각각 14393개와 14887개였다.....
이러니 task들이 몇 만개씩 생기지......😱
수행되어야 할 task 개수가 44878개....
해결방법
따라서 아 필터링된 아이디값의 데이터들을 hdfs로 쓸 때 개수를 줄여 쓰는 것 부터 다시 해야겠다라고 판단하고 rdd를 save하기전 coalesce(20)을 주어 14393개로 나뉘어진 파티션들을 20개의 파티션으로 나뉘어 쓰이도록 수정해 주었다.
그리고 ID값을 기준으로 두 데이터를 Join이후 distinct하고 counting하는 작업도 굉장히 늦었기에 join이후에 repartition으로 파티션의 개수를 줄여주고 counting을 하도록 수행해주었다.(실제 ID값으로 Join을 하게 되면 데이터가 줄어들기 때문에 많은 파티션을 유지할 필요가 없다.) coalesce와 repartition은 둘다 파티션의 개수를 조절해주는 메서드인데 차이가 궁금하신 분들은 이전 포스팅을 참고 바랍니다.
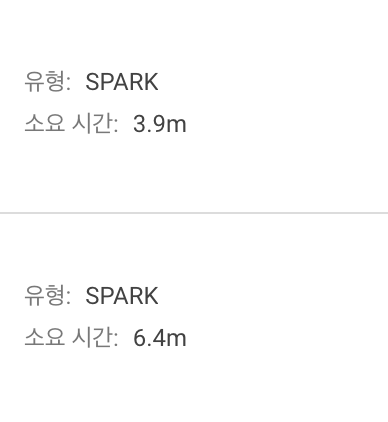
이렇게 수정을 하고 수행하였더니 task개수도 확 줄어들고수행시간도 5~7분이내에 다 끝나는 것을 확인할 수 있었다.
task들의 개수가 몇만개에서 몇 십 몇 백개 단위로 확 줄어든 것을 확인 할 수 있다.작업 시간도 1~2시간 걸려도 안끝나던데 훅~줄었다.
Spark 데이터 처리 작업시 고려사항
간만에 데이터 추출작업을 하다보니 미처 늦게 인지한 부분도 없지 않아 있었다. 이렇게 사이즈가 큰 데이터를 처리할 때는 항상 파티션의 개수를 잘 조절해서 처리하길 바란다. 그리고 스파크 성능에 영향을 미치는 부분에는 많은 부분이 있지만 기본적으로 데이터들의 파티션과 spark를 수행할 때 기본적인 executor개수와 core의 개수 executor 메모리 설정만 적합하게 되도(이 적합하게가 힘듬...) 큰 문제 없이 사용할 수 있을 거라 생각한다.
기본적으로 HDFS 블록의 사이즈가 64,128,256MB (하둡 배포판에 따라 상이)인건 알고 계실텐데요? 왜 그렇고 어떻게 블록이 처리되는지에 대해 정리해보겠습니다. 해당 내용은 '하둡 완벽 가이드'의 내용을 학습하고 반복 학습겸 정리한 내용입니다.
블록
일반적으로 물리적인 디스크는 블록 크기란 개념이 있습니다. 블록 크기는 한 번에 읽고 쓸 수 있느 데이터의 최대량입니다.
보통 파일시스템의 블록의 크기는 수 킬로바이트고, 디스크 블록의 크기는 기본적으로 512byte입니다.
반면 HDFS도 블록의 개념을 가지고 있지만 HDFS의 블록은 기본적으로 128MB와 같이 굉장히 큰 단위입니다. HDFS의 파일은 단일 디스크를 위한 파일시스템처럼 특정 블록 크기의 청크로 쪼개지고 각 청크(chunk)는 독립적으로 저장됩니다. 단일 디스크를 위한 파일시스템은 디스크 블록 크기보다 작은 데이터라도 한 블록 전체를 점유하지만, HDFS 파일은 블록 크기보다 작은 데이터일 경우 전체 블록 크기에 해당하는 하위 디스크를 모두 점유하지는 않습니다.
예를 들어 HDFS의 블록 크기가 128MB고 1MB 크기의 파일을 저장한다면 128MB의 디스크를 사용하는 것이 아니라 1MB의 디스크만 사용합니다.
블록은 내고장성(fault tolerance)과 가용성(availability)을 제공하는 데 필요한 복제(replication)를 구현할 때 매우 적합합니다.. 블록의 손상과 디스크 및 머신의 장애에 대처하기 위해 각 블록은 물리적으로 분리된 다수의 머신(보통 3개)에 복제되며 만일 하나의 블록을 이용할 수 없는 상황이 되면 다른 머신에 있는 복사본을 읽도록 클라이언트에 알려주면 됩니다. 블록이 손상되거나 머신의 장애로 특정 블록을 더 이상 이용할 수 없으면 또 다른 복사본을 살아 있는 머신에 복제하여 복제 계수(replication factor)를 정상 수중으로 돌아오게 할 수 있습니다.
일반적인 디스크 파일시스템과 같이 HDFS의 fsck 명령어로 블록을 관리할 수 있습니다.
> hdfs fsck / -files -blocks
파일시스템에 있는 각 파일을 구성하는 블록의 목록이 다음과 같이 출력됩니다.
기본 /(루트) 부터 순차적으로 디렉토리 들을 돌며 블록 상황을 보여줍니다.
HDFS 블록이 큰 이유는?
HDFS 블록은 디스크 블록에 비해 상당히 크다. 그 이유는 탐색 비용을 최소화하기 위해서다. 블록이 매우 크면 블록의 시작점을 탐색하는 데 걸리는 시간을 줄일 수 있고 데이터를 전송하는 데 많은 시간을 할애할 수 있다.(블록이 작고 너무 많으면 시작점을 탐색하는 비용 증가) 따라서 여러 개의 블록으로 구성된 대용량 파일을 전송하는 시간은 디스크 전송 속도에 크게 영향을 받는다.
탐색 시간이 10ms고 전송률이 100MB/s 라고 하면, 탐색 시간을 전송 시간의 1%로 만들기 위해서는 블록 크기를 100MB로 정하면 된다. 하둡 배포판에 따라 다르지만 블록 크기의 기본값은 128MB다. 기본 블록 크기는 디스크 드라이브의 전송 속도가 향상될 때마다 계속 증가할 것이다.