당신이 현재하는 사소한 행위는 잔잔한 물결처럼 서서히 퍼져나가 모든 이에게 영향을 줍니다. 당신의 마음가짐이 다른 이의 가슴에 불을 지필 수도, 근심을 초래할 수도 있습니다. 당신의 숨소리가 사랑의 빛을 뿜어낼 수도, 우울함으로 온 방안을 어둡게 만들 수도 있습니다. 당신의 시선이 즐거움을 선사할 수도 있으며, 당신의 언어가 자유를 향한 열망을 독려할 수도 있습니다. 당신의 행동 하나하나가 다른 이들의 생각과 마음을 열 수 있습니다.
DAVID DEIDA
사회운동가형 사람은 카리스마와 충만한 열정을 지닌 타고난 리더형입니다. 인구의 대략 2%가 이 유형에 속하며, 정치가나 코치 혹은 교사와 같은 직군에서 흔히 볼 수 있습니다. 이들은 다른 이들로 하여금 그들의 꿈을 이루며, 선한 일을 통하여 세상에 빛과 소금이 될 수 있도록 사람들을 독려합니다. 또한, 자신뿐 아니라 더 나아가 살기 좋은 공동체를 만들기 위해 사람들을 동참시키고 이끄는 데에서 큰 자부심과 행복을 느낍니다.
진심으로 사람을 믿고 이끄는 지도자
우리는 대개 강직한 성품을 가진 이에게 마법처럼 끌리곤 합니다. 사회운동가형 사람은 진정으로 타인을 생각하고 염려하며, 그들이 필요하다고 느낄 때면 발 벗고 나서서 옳은 일을 위해 쓴소리하는 것을 마다하지 않습니다. 다른 이들과 별 어려움 없이 잘 어울리며, 특히 사람들과 직접 얼굴을 보고 의사소통하는 것을 좋아합니다. 이들에게 내재되어 있는 직관적 성향은 이성적 사실이나 정제되지 않은 인간의 본래 감정을 통하여 다양한 사람의 성격을 더 잘 파악하고 이해하게 합니다. 타인의 의도나 동기를 쉽게 파악 후 이를 그와 개인적으로 연관 짓지 않으며, 대신 특유의 설득력 있는 웅변 기술로 함께 추구해야 할 공통된 목표를 설정하여 그야말로 최면에 걸린 듯 사람들을 이끕니다.
진심으로 마음에서 우러나 타인에게 관심을 보이는 이들이지만 간혹 도가 지나쳐 문제가 될 때도 있습니다. 일단 사람을 믿으면 타인의 문제에 지나치리만치 관여하는 등 이들을 무한 신뢰하는 경향이 있습니다. 다행히도 이들의 진심 어린 이타주의적 행동은 다른 이들로 하여금 더 나은 사람이 될 수 있도록 독려한다는 차원에서 자기 계발을 위한 자아실현 기제로 작용하기도 합니다. 하지만 자칫 잘못하면 이들의 지나친 낙관주의는 되려 변화를 모색하는 이들의 능력 밖이거나 그들이 도울 수 있는 범주를 넘어서는 일이 될 수도 있습니다.
사회운동가형 사람이 경험할 수 있는 또 다른 오류는 이들이 그들 자신 감정을 지나치게 투영하고 분석한다는 점입니다. 다른 사람의 문제에 지나치리만치 깊이 관여하는 경우, 자신의 잘못에서 비롯된 일이 아님에도 불구하고 타인의 문제를 마치 본인의 문제로 여겨 자칫하면 정서적 심기증(hypochondria)과 같은 증상을 보일 수도 있습니다. 더욱이 타인이 문제를 해결하는 데 한계에 도달하였을 때 이를 해결하는 데 자신이 어떠한 도움이 될 수 없음에 딜레마에 빠지기도 합니다. 이러한 오류를 범하지 않기 위해서는 사회운동가형 사람은 그 상황에서 한발 뒤로 물러나 본인이 느끼는 감정과 타인의 문제를 객관적으로 분리해 다른 각도에서 바라볼 필요가 있습니다.
사회정의 구현을 위해 어려움에 맞서 싸우는 이들
사회운동가형 사람은 말과 행동이 일치하며, 타인을 진심으로 대합니다. 중독성 강한 이들 특유의 열정으로 사람들 간의 화합을 도모하고 변화를 이끌 때 이들은 그 어떤 때보다도 큰 행복을 느낍니다.
사회운동가형의 과도한 이타주의적 성격은 자칫하면 되레 문제를 야기하기도 합니다. 이들은 그들이 옳다고 믿는 생각이나 이념 실현을 위해 다른 이를 대신하여 총대를 메는 것을 두려워하지 않습니다. 이를 볼 때 다수의 영향력 있는 정치인이나 지도자가 이 유형에 속하는 것이 어찌 보면 당연한지도 모릅니다. 경제적 부를 창출하기 위해 나라를 이끄는 한 국가의 원수에서부터 버거운 경기를 승리로 이끄는 어린이 야구팀 코치에 이르기까지 이들은 더 밝은 미래 구현을 위해 앞장서서 사람들을 이끄는 것을 좋아합니다.
오바마 대통령^_^
가끔은 내 자신을 뒤돌아보고 나는 어떤사람인지 생각해보는 시간을 가져보면 좋을 것 같다.
이로인해 내가 무엇을 원하고 뭘 하고 싶은지에 대해 알게되고 현재에 안주하기보단 조금씩이라도 발전해갈 수 있을거라 생각한다.
먼저 블로그에 대한 부분이다. 어느 순간 부터 잘쓰기 위해 공들이는 포스팅보다 정말 내게 도움이되었고 추후에도 필요할 것 같은 내용들을 중심으로 포스팅하자고 마음먹었었다. 그 후 부터는 포스팅을 하는데 아무래도 부담감이 많이 줄게 되었고 포스팅 자체에 대한 즐거움을 찾은 것 같다. 물론 그런 포스팅에도 봐주시는 분들이 계시고 꾸준히 조회수가 올라가는 것도 한 몫 하고 있다.
이번 년도에는 유튜브라는 컨텐츠 시장에 내 컨텐츠들을 만들어서 테스트해보는데 좀 더 중점을 두고 싶어 블로그는 꾸준히 한 달에 3개 정도의 목표만을 잡았던 것 같다.
일단 목표는 성취했다. 이번 년도에 포스팅 한 글의 수는 46개!!! 이번 회고글까지 포함시키면 47개를 작성하게 된다.
포스팅 하나 빼고는 모두 전공과 관련된 포스팅을 작성했엇고 의도하진 않았지만 다양한 카테고리에 골고루 글을 썼던 것 같다.
꾸준히 하고 있어서 인지 하루 방문자 수도 작년과 비교했을 때는 많이 올랐다.
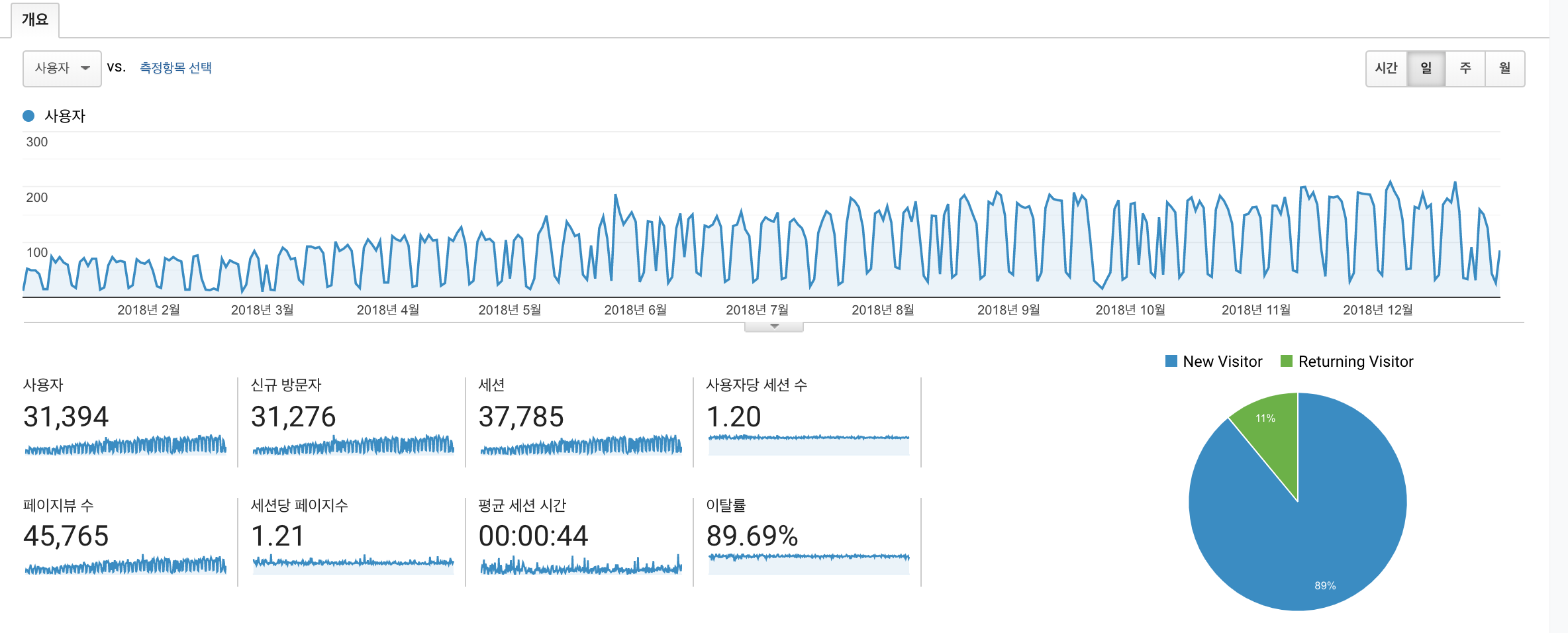
2018년 블로그 통계 기준 (google analytics)
2018 google analytics
2019년 블로그 통계 기준 (google analytics)
2019 google analytics
신규방문자도 그렇고 페이지뷰 수도 그렇고 약 2배정도 증가한 것 을 볼 수 있다. 물론 이렇게 증가할지는 몰랐지만 결과적으로 꾸준히 포스팅을 하며 글이 차곡 차곡 쌓여가다 보니 자연스레 방문자 수도 증가한 것 같다.
2020년에도 꾸준히 블로그를 할 수 있길 희망해 본다.
2. 전공도서 꾸준히 읽기
사실 2020년 초반에 욕심을 한 껏 부려 책을 양껏 샀었다...
2019년 초반에 산 책
이 책들을 구입하게 된 배경에는 무슨 바람이 불었는진 모르겠지만 뭔가 언어관련 전공 책 이외의 전공 관련 책들을 많이 읽고 싶어 인터넷에서 여러 개발자들이 리뷰해 논 책들 중 관심있는 것들만 골라 담아 한 번에 구매했었다...무려 책값만 19만원.
이 중 반만이라도 읽으면 성공이겠다고 생각을 했으나 반은 커녕 2/5정도의 되는 책들만 읽은 것 같다. 그 중에서는 뭔가 내가 생각했던 내용과 맞지 않아 혹은 내게 별로 와닿지 않는 내용들이 주를 이루어 몇 페이지 넘기다 스킵해 버린 책도 있다.(ex, 해커와 화가, 디자인 해커)
'이펙티브 프로그래밍'과 '폴리그랏 프로그래밍', 객체지향의 사실과 오해, 피플웨어(조금) 정도 읽었다.
이 중 가장 재미있게 읽었던 책은 '이펙티브 프로그래밍'이였다. 실제로 이 책을 재미있게 읽고 유튜브 컨텐츠로도 만들어 보았지만 영상의 내용은 부실했는지 조회수가 잘 나오진 않았다ㅠㅠ 혹시나 궁금하신 분들은 아래의 유튜브 링크를...좋아요와 ㄷㅐㅅ글은 큰..힘.이됩니..다..
보통 서점에 가서 내용을 보고 책을 사는 스타일인데 19년에는 직접 내용을 보지도 않고 질러놔버린 전공 책들로 인해 서점에 들러 책보는 시간이 많이 부족했던 것 같다...사논 책부터 다 읽자라는 생각때문에.....다음 부터는 꼭 서점에서 내용을 읽고 그 때 그때 내게 필요한 책을 사서 보리라 다짐해 본다.
3. 토이프로젝트 진행하기
실제 이번년도 7월 부터 회사 동기와 함께 진행하고 있는 토이프로젝트가 하나 있다. 아직은 밝히기 힘들고 2020년 3월 1일 베타오픈을 해볼 예정을 가지고 있다. 이 때가 된다면 다시 한 번 내용을 정리해보도록 하겠다.
무튼 회사 업무 이외에도 토이프로젝트로 꾸준히 코딩을 하려고 노력했다.
4. 업무에 대한 성과 인정 받기
일단 회사에 속해 개발업무를 하고 있는 개발자이기 때문에 우선적으로 회사 일을 가장 중점에 두고 있다. 하지만 이번 년도에는 나의 의지와는 상관없이 조직 개편이 여러 번 되고 위의 리더급도 여러번 바뀌다 보니 조금 의지가 많이 꺾이기도 했던 한 해 였던 것 같다. 그 와중에 팀원 한 명의 이직도 겹쳐 정신없는 하반기를 보냈던 것 같다. 하지만 그 와중에도 맡은 업무에 대해서는 책임감 있게 처리하려고 노력했던 것 같고 항상 그 결과에 대한 내용을 정리하고 공유하려 했던 것 같다. 물론 이번 년도에는 특정 프로젝트성 업무보다는 유지보수성 업무가 많아 좀 더 개인적으로 재미는 많이 느끼지 못했던 것 같다. 내년에는 좀 더 데이터 기반의 다양한 프로젝트들을 진행해보고 싶고 무엇보다 기존 API시스템을 webfulx를 이용해 전체적인 개편을 해보고싶은데.....할 수 있을지는 잘 모르겠다.
무튼 2020년에도 다양한 업무를 하며 좀 더 인사이트를 넓혀 나갈 예정이다.
[ 전공 이외의 목표 ]
1. 운동 꾸준히 하기
개인적으로 평일 저녁은 약속이 없는 한 최소 1시간에서 1시간 40분 정도 회사에 있는 헬스장에서 운동을 한다.
이번년도에는 몇일이나 운동을 했는지 다이어리를 살펴 보았다.
1년 365일 중 운동을 한 날은 248일이였다.(일일히 다이어리에 적힌 운동한 날을 세어봄.....☠️) +- 5%
그래도 항상 운동을 꾸준히 하려고 노력하였고 17년 운동일지 써논 것들을 보며 strength나 몸이 많이 성장했음을 느낀다.
2020년에도 건강히(이번에 손목을 다쳐서 강제 1주일 휴식중...) 즐겁게 운동할 예정이다.
2020년도 화이팅!
2. 유튜브(youtube)에 컨텐츠 6개 이상 업로드 해보기
실제 '부의 추월차선'이라는 책을 읽고 컨텐츠를 만들어 내는 사람이 되어야 겠다고 생각했고 할 수 있는 다양한 것들을 시도해 보고 싶었다. 그 중에는 블로그 포스팅(글), 유튜브(영상), 서비스(토이프로젝트)를 목표로 삼았고 19년에는 영상 컨텐츠를 만들고 싶은 욕구가 강했다. 하지만 영상편집이 뭔 줄도 모르고 막상 유튜브를 시작하는 법을 모르다 보니 막연한 두려움을 가지고 있었다. (사실 18년도 중반 이후부터 생각은 있었지만 미루고 미룸...) 하지만 역시 시작이 반이라고 한 번 올리고 나니 별거 아니라는 생각이 들었다. 그렇게 이번 년도 총 22개의 영상을 올리게 되었다. 물론 처음 몇개의 영상은 테스트성 영상도 포함되어 있지만 지금에 와서 돌아보니 꽤나 뿌듯하다.
하지만 유튜브를 하면서 자괴감도 많이 겪었다. 영상을 올려도 조회수가 100을 넘는데 한 달씩 걸렸던 적도 있다......구독자수는 무슨 시작만하면 금방 천명 찍을줄알았는데 무슨;;^^😭ㅋㅋ...그래도 포기하더라도 최소 3년은 해보자라는 마음가짐으로 시작했기에 내년에는 2주에 하나씩 꾸준히 올리는 것을 목표로 해 볼 예정이다. (가능하겠지....?)_🧐
내년에는 좀 더 체계화 된 내용을 가지고 영상을 지속적으로 업로드 해봐야겠다.
3. 영어공부 꾸준히 하기
사실 제일 지키지 못한 부분.,...실제 업무에서도 단순 영어로 된 문서를 읽는데 그치고 사용할 일이 없으니 지속적인 동기부여를 얻기가 힘든게 제일 큰 요인인 것 같다. 매년 계획은 세우고 있지만 항상 우선순위가 밀리게 된다는.....목표는 업무를 영어로 자유로이 할 수 있는 정도인데.....이렇게 하다간 10년이 걸려도 힘들듯하다;;;
4. 비전공도서 6권 이상 읽기
사실 비전공도서 6권이라고 하면 적어 보일 수 있겠지만 항상 독서노트를 쓰며 읽는 내게는 적당한 책의 권수라 생각한다. 한 권을 읽을 때 내게 와닿았던 구절이나 두고두고 보고 싶은 구절들을 다 독서노트에 옮겨가며 곱씹어가며 읽는 스타일이다. 따라서 책 1권을 읽는데 꽤나 시간이 많이 걸린다. 그래도 목표했던 권수는 다 채웠다.
내년에는 30,40대의 기반이 될 수 있는 나만의 지식 '독서노트'를 채워나가는데 집중해 보려 한다. 23살 때 연습장 한 권 분량의 독서노트를 작성헀었는데 그게 아직 까지 내게 큰 자산으로 남아있다. 힘들때면 위로를 매너리즘에 빠졌을 때는 동기부여를 주는 소중한 내 보물로 자리 잡았다. 지식은 복리개념이라고 했다. 한 발 앞써 쌓아 나갈 때 그 효과는 배가 될 것 이다. 2020년 남은 30, 40대를 위한 독서노트를 준비해보자.
오늘 포스팅은 2019년을 전반적으로 회고하며 적어 보았다. 나름 하루 하루 충실하게 보내려고 노력해왔지만 뒤돌아 보았을 때 그렇지 못한 날도 많았던 것 같다. 2020년에는 좀 더 시간을 체계적으로 사용하고 많은 지식을 쌓을 수 있는 사람이 되어야 겠다.
현재 데이터를 다루는 업무도 하고 있다 보니 항상 데이터에 대한 품질 및 비정상적인 데이터 유입 및 처리 방법에 대해서도 관심을 가지고 있습니다. 이에 관련해서 SK 기술 블로그에 Spark Streaming을 사용해 탐지 프로세스를 정리한 글이 있어 추후 관련 시스템을 개발시나 유사한 모듈 개발시 많은 도움을 받을 수 있을 것 같아 남겨봅니다.
자바8버전 이상을 쓰시는 분들은 lamda나 stream을 많이 사용하실 텐데요. 관련해서 좀 더 stream을 잘 사용할 수 있는 방법과 일반적으로 그냥 stream을 썼을 때 놓칠 수 있는 부분들이 잘 정리되어 있어 공유해봅니다. 해당 블로그로 가보시면 stream 총정리글도 있으니 아직 자바8 stream에 대해 익숙하지 않으신 분들도 도움을 받으실 수 있을 거라 생각합니다.
쿠팡이 데이터를 처리하는 시스템이 발전해가는 모습을 소개하며 어떻게 데이터를 다루고 있는지에 대해 잘 정리된 글입니다. 꼭 해당 글이 쿠팡의 데이터 처리 history만 설명하고 있다기 보다는 전반적으로 2010년 부터 데이터를 다루는 많은 회사들이 발전해 온 모습을 담고 있지 않나 생각해봅니다. 데이터 엔지니어들이 하는 업무가 궁금하시거나 대용량의 데이터들은 어떻게 처리되는지 궁금하신 분 들, 현업에서 데이터엔지니어로 일하시고 있는 분들이 읽으면 매우 좋을 것 같습니다.
클라이언트와 접해 있는 시스템을 운영하다 보면 정말 많은 장애들을 맞닥드리게 되고 해당 장애를 처리하며 또 다른 사이드이펙트를 경험한 적이 있으실 겁니다. 우아한형제들 광고시스템팀의 개발자분이 그동안 경험했던 다양한 문제상황들을 얘기하며 주의해야 할 부분들에 대해 설명해주시고 있습니다. 읽어보시면 아시겠지만 분명 내가 장애를 냈던 상황과 유사한 내용이 있어 뜨끔하실지도 모르겠습니다.
해당 블로그에 정리된 것들만 조심해도 우리는 크리티컬한 장애를 예방하는데 많은 도움을 얻을 수 있을 거라 생각합니다.
최근 사이즈가 큰 대략 두 데이터 각각 2TB (2000GB) 정도의 데이터의 ID값들을 JOIN시켜 얼마나 일치하는지 확인하는 작업을 진행하였다. 간만에 들어온 Adhoc요청에 요구사항 파악이 먼저였고 "사이즈가 커봤자 스파크가 executor개수와 core개수 excetuor memory설정만 맞춰주면 잘 돌리면 되겠다."라고 생각했었다.
하지만 사이즈가 크다보니 실제 운영 클러스터에서 spark-shell에 접속해 command를 날리는건 클러스터의 실제 운영되는 작업에 영향을 줄 수 있기에 일정 부분의 데이터들을 떼와 로컬 Spark 모듈 프로젝트를 통해 원하는대로 파싱하고 조인해서 결과값이 나오는지 먼저 확인하였다.
두 데이터 각각 2TB들을 가공해 뽑아야 하는 조건은 15가지 정도 되었고 나는 해당 코드작업을 하고 jar파일로 말아 특정 리소스풀을 사용하는 조건과 스파크 설정값들을 알맞게 설정해 spark-submit을 실행할 예정이었다.
작업에 대해 설명하기 전에 클러스터 규모에 대해 간단히 언급하자면 실제 서비스를 운영하는 클러스터는 아니였고
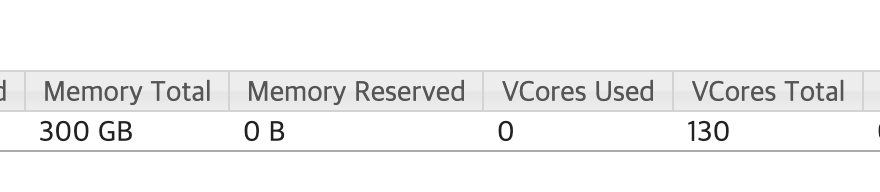
Data Lake로 사용되는 데이터노드 5대로 이루어진 규모가 그렇게 크지 않은 클러스터였다.
가용 가능 최대 메모리는 300GB, VCore 개수는 130개 정도 규모
데이터 추출의 첫 번째 조건
특정 action을 했던 ID값들을 뽑아 distinct하고 counting하는 작업이었다.
물론 데이터사이즈가 크긴했지만 단순한 작업이였기에 그렇게 오래는 걸리지 않을거라고 예상했다 (20분 이내 예상)
실제 Spark-submit을 수행하였고 각 파일들을 읽어들여 카운팅 작업이 수행되는 것을 Spark에서 제공하는 Application UI을 통해 어떤 작업 현재 진행중인지 executor들을 잘 할당되어 일을 하고 있는지를 모니터링 하였다.
근데 이게 왠걸??? Couning을 하는 단계에서 실제 action이 발생했고 (Spark는 lazy연산이 기본) 시간이 너무 오래걸리는 걸 발견하였다...한 시간 이상이 지나도 끝나지 않은 것으로....기억한다.
따라서 이대로는 안되겠다 싶어 일단 요구사항들 중 한번에 같이 처리할 수 있는 그룹 세개로 나누고 기존 데이터를 가지고 처리할게 아니라 특정조건으로 filterling이 된 실제 필요한 데이터들만 가지고 작업을 해야겠다고 생각했다.
그래서 일단 원하는 조건으로 filterling을 한 후 해당 데이터들만 hdfs에 다시 적재했다.
실제 처리에 사용될 데이터 사이즈가 2~4G로 훅 줄었고 (다른 값들을 다 버리고 조건에 맞는 실제 ID값만 뽑아냈기 때문) 이제 돌리면 되겠다 하고 생각하고 돌렸다.
그런데...데이터 사이즈가 2~4G밖에 안되는 데이터들간 Join을 하고 Counting을 하는 작업이 무슨 20~30분이나 걸린단 말인가?....(1~3분 이내를 예상했음)
그래서 이전에 비슷한 상황에서 실제 데이터들의 파티션이 데이터 사이즈에 비해 너무 많이 나누어져 있어서 Spark가 구동되며 execution plan을 세울 때 많은 task들이 발생되어 성능이 떨어졌던 기억이 있어 필터링 한 데이터들의 파티션 개수를 세어 보았더니...
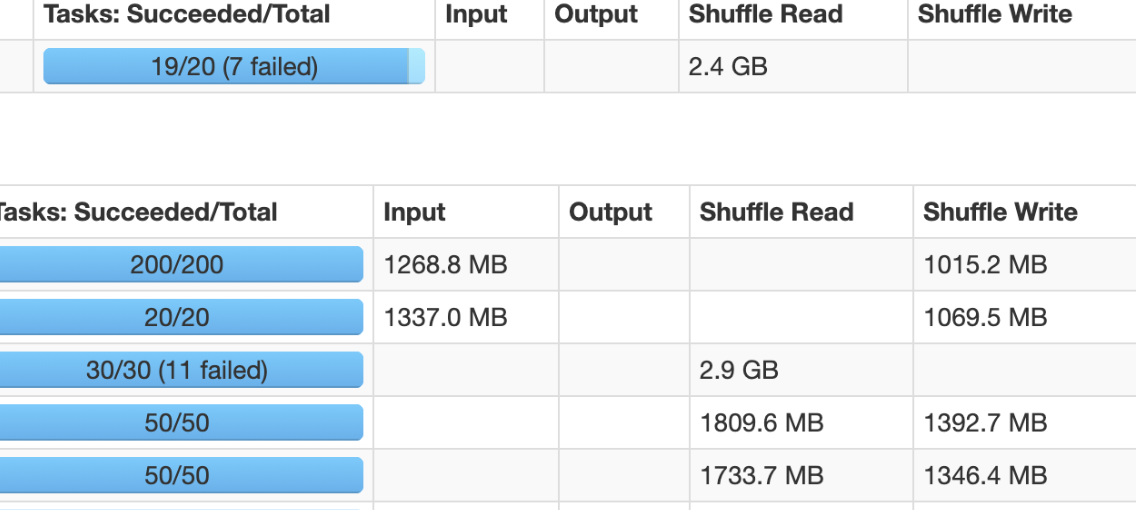
사이즈가 2.6G가 밖에 안되는 실제 사용될 데이터의 파일의 개수가....각각 14393개와 14887개였다.....
이러니 task들이 몇 만개씩 생기지......😱
수행되어야 할 task 개수가 44878개....
해결방법
따라서 아 필터링된 아이디값의 데이터들을 hdfs로 쓸 때 개수를 줄여 쓰는 것 부터 다시 해야겠다라고 판단하고 rdd를 save하기전 coalesce(20)을 주어 14393개로 나뉘어진 파티션들을 20개의 파티션으로 나뉘어 쓰이도록 수정해 주었다.
그리고 ID값을 기준으로 두 데이터를 Join이후 distinct하고 counting하는 작업도 굉장히 늦었기에 join이후에 repartition으로 파티션의 개수를 줄여주고 counting을 하도록 수행해주었다.(실제 ID값으로 Join을 하게 되면 데이터가 줄어들기 때문에 많은 파티션을 유지할 필요가 없다.) coalesce와 repartition은 둘다 파티션의 개수를 조절해주는 메서드인데 차이가 궁금하신 분들은 이전 포스팅을 참고 바랍니다.
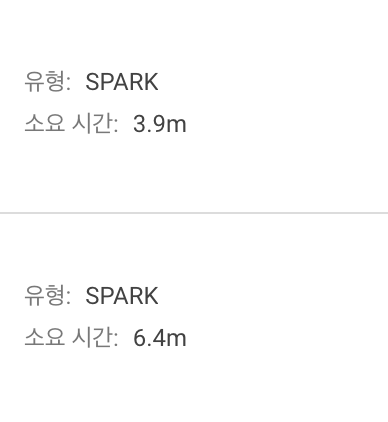
이렇게 수정을 하고 수행하였더니 task개수도 확 줄어들고수행시간도 5~7분이내에 다 끝나는 것을 확인할 수 있었다.
task들의 개수가 몇만개에서 몇 십 몇 백개 단위로 확 줄어든 것을 확인 할 수 있다.작업 시간도 1~2시간 걸려도 안끝나던데 훅~줄었다.
Spark 데이터 처리 작업시 고려사항
간만에 데이터 추출작업을 하다보니 미처 늦게 인지한 부분도 없지 않아 있었다. 이렇게 사이즈가 큰 데이터를 처리할 때는 항상 파티션의 개수를 잘 조절해서 처리하길 바란다. 그리고 스파크 성능에 영향을 미치는 부분에는 많은 부분이 있지만 기본적으로 데이터들의 파티션과 spark를 수행할 때 기본적인 executor개수와 core의 개수 executor 메모리 설정만 적합하게 되도(이 적합하게가 힘듬...) 큰 문제 없이 사용할 수 있을 거라 생각한다.
쓰레드의 개념적인 내용과 Life Cycle의 간단한 설명과 함께 Slow Query를 실행하는 애플리케이션을 구현하고 이를 테스트 하는 과정을 체계적으로 설명하고 있다. 이 과정에서 발생하는 CLOSE_WAIT이 많이 쌓이는 이슈 및 쓰레드 덤프를 통한 분석에 대한 내용까지 일목요연하게 다루고 있어 실제 Database나 외부 시스템들과의 연계된 어플리케이션을 개발하고 있다면 꼭 읽어 보고 이러한 상황에도 유연하게 대처할 수 있도록 하자.
실제 spark 작업을 통해 데이터를 뽑는 adhoc작업도 간혹 진행하고 있는데 이 때마다 실제 운영서버의 spark-shell을 열어 작업을 했었다. 이로 인한 문제점은 spark-shell의 작업으로 인해 실제 운영서버에서 돌아야할 작업들이 리소스 부족으로 악영향을 받는 상황이 발생할 수 있다는 것이다. 하지만 편리상 spark-shell로 작업을 진행했었는데 앞으로는 작업해야할 내용들을 실제 로컬환경에 환경을 구성해 돌려보고 해당 작업이 완성되었을 때 spark-submit을 통해 configuration을 적절히 설정하여 돌리기로 맘먹었고 로컬에 환경을 구성할 때 참고했던 블로그이다. spark1.5, 1.6 버전대와 spark2버전대 scala+gradle template을 만들어 놓았는데 필요한 분이 있다면 공유드릴 수 있도록 하겠다.
Spark의 메모리 관리에 대해 잘 정리된 글로 실제 Spark를 사용해본 분들은 알겠지만 out of memory error가 자주 잘 발생한 경험이 있을 것이다. 메모리 기반 연산처리를 하기 때문인데 Spark가 메모리를 어떻게 사용하고 어떻게 Config를 구성하여 작업하면 좋은지 정말 잘 깔끔하게 정리되어 있고 심도 있는 내용까지 다룬다.
일급 컬렉션이 뭔지 궁금하신분? 객체지향적 리팩토링하기 쉬운 코드로 가기 위해서는 왜 일급 컬렉션을 써야하는지 예시와 함께 잘 정리된 글이다. 해당 포스팅의 저자는 Enum과 마찬가지로 일급 컬렌션은 객체지향 코드로 가기 위해 꼭 익혀야할 방법 중 하나라고 소개하고 있다.
스프링이나 자바프로젝트에서 jdbc tempate으로 hive명령어 날릴 때 쿼리문에 ';'(세미콜론)을 붙혀 statement를 execute하지 않도록 하자. 세미콜론이 쿼리에 들어 있으면 다음과 같은 에러를 뱉을 것이다.
Caused by: org.apache.hive.service.cli.HiveSQLException: Error while compiling statement: FAILED: ParseException line 1:519 cannot recogni input near ';' '<EOF>' '<EOF>' in expression specification
at org.apache.hive.service.cli.operation.Operation.toSQLException(Operation.java:326)
at org.apache.hive.service.cli.operation.SQLOperation.prepare(SQLOperation.java:102)
at org.apache.hive.service.cli.operation.SQLOperation.runInternal(SQLOperation.java:171)
at org.apache.hive.service.cli.operation.Operation.run(Operation.java:268)
at org.apache.hive.service.cli.session.HiveSessionImpl.executeStatementInternal(HiveSe
이유는 스택오버플로우의 답변으로 대신한다.
Using ; in a query for most databases doesn't work as it is usually not part of the statement syntax itself, but a terminator for command line or script input to separate statements. The command line or script processor sees a semi-colon as the signal that the statement is complete and can be sent to the server. Also in JDBC a single statement prepare (or execute) should only be one actual statement so multiple statements are not allowed and so there is also no need to have a semi-colon, and as for some (most?) databases the semi-colon isn't part of the statement syntax, it is simply a syntax error to have one included. If you want to execute multiple statements, you need to use separate executes. Technically, MySQL does have an option to support multiple executions which can be enabled by a connection property. This behavior is not compliant with the JDBC specification/API and makes your code less portable. See allowMultiQueries on Driver/Datasource Class Names, URL Syntax and Configuration Properties for Connector/J
--------
Having semicolons in JDBC statements is very error prone in general. Some JDBC drivers do not support this (e.g. IBM's JDBC driver for DB2 10.x throws an exception if you close your SQL statement with ";").