java.sql.SQLException: The server time zone value 'KST' is unrecognized or represents more than one time zone. You must configure either the server or JDBC driver (via the serverTimezone configuration property) to use a more specifc time zone value if you want to utilize time zone support.
mysql-connector-java 버전 5.1.X 이후 버전부터 KST 타임존을 인식하지 못하는 이슈로
org.apache.solr.client.solrj.SolrServerException: Server refused connection at: http://127.0.0.1:8983/solr atorg.apache.solr.client.solrj.impl.HttpSolrClient.executeMethod(HttpSolrClient.java:650) at . . . java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) at java.lang.Thread.run(Thread.java:748) Caused by: org.apache.http.conn.HttpHostConnectException: Connect to 127.0.0.1:8983 [/127.0.0.1]failed: Connection refused (Connection refused) at org.apache.http.impl.conn.DefaultHttpClientConnectionOperator.connect(DefaultHttpClientConnectionOperator.java:159) at org.apache.http.impl.conn.PoolingHttpClientConnectionManager.connect(PoolingHttpClientConnectionManager.java:373) at org.apache.http.impl.execchain.MainClientExec.establishRoute(MainClientExec.java:394) at org.apache.http.impl.execchain.MainClientExec.execute(MainClientExec.java:237)
해당 프로젝트에서는 spring-boot-starter-data-solr를 사용하고 있었고 spring-boot-starter-actuator dependency를 추가하고
application.properties에 다음과 같이 추가해주었다. actuator사용을 위해서!
management.health.solr.enabled=false한줄을 application.properties에 추가해주어 처리해주었다. 뭔가 actuator내부적으로 solr를 사용하고 있어 포트가 충돌나지 않았나 싶다. 이에 actuator설정에서 저렇게 false로 명시해주니 정상적으로 동작하는 것을 확인하였다.
OrderBy는 단순히 sort function의 alias라는점!!!...결국 동일하다는 얘기
[ Spark documentation ] /** * Returns a new Dataset sorted by the given expressions. * This is an alias of the `sort` function. * * @group typedrel * @since 2.0.0 */ @scala.annotation.varargs def orderBy(sortCol: String, sortCols: String*): Dataset[T] = sort(sortCol, sortCols : _*)
19/06/27 18:27:47 INFO mapreduce.Job: Running job: job_1559692026802_4689
19/06/27 18:27:56 INFO mapreduce.Job: Job job_1559692026802_4689 running in uber mode : false
19/06/27 18:27:56 INFO mapreduce.Job:map 0% reduce 0%
19/06/27 18:28:14 INFO mapreduce.Job:map 19% reduce 0%
19/06/27 18:28:15 INFO mapreduce.Job:map 39% reduce 0%
(생 략)
19/06/27 18:28:42 INFO mapreduce.Job:map 100% reduce 99%
19/06/27 18:28:43 INFO mapreduce.Job:map 100% reduce 100%
19/06/27 18:28:46 INFO mapreduce.Job: Job job_1559692026802_4689 completed successfully
결 론
Reducer를 많이 늘린다고해서 처리 속도가 비례해서 향상되는 것은 아니다. 해당 작업의 유형을 고려하고 Reducer개수를 조절해가며 최적의 개수를 찾는게 중요하다. Reducer개수에 따라 결과 데이터가 hdfs에 쓰여진다.(Reducer10개면 10개의 파티션으로, 5개이면 5개의 파티션으로)
마지막으로 하둡 완벽가이드(4판)의 내용을 첨부한다.
리듀서를 하나만 두는 것(기본값)은 하둡 초보자가 자주 범하는 실수다. 실제로 대부분의 잡은 리듀서 수를 기본값인 1보다 크게 설정하는 것이 좋다. 그렇지 않으면 모든 중간 데이터가 하나의 리듀스 태스크로 모여들기 때문에 잡이 굉장히 느려진다. 사실 잡의 리듀서 수를 결정하는 것은 과학보다는 예술에 가깝다. 보통 리듀서 수를 늘리면 병렬 처리 개수도 늘어나서 리듀스 단계에서 걸리는 시간을 줄일 수 있다. 그러나 너무 많이 늘리면 작은 파일이 너무 많이 생성되는 준최적화(suboptimal)에 빠지게 된다. 경험적으로 리듀서의 실행 시간은 5분 내외, 출력 파일의 HDFS 블록 수는 최소 1개로 잡는 것이 좋다.
19/06/19 11:16:49 INFO mapreduce.Job: Task Id : attempt_1559692026802_2824_m_000031_2, Status : FAILED Error: Found interface org.apache.hadoop.mapreduce.Counter, but class was expected 19/06/19 11:16:49 INFO mapreduce.Job: Task Id : attempt_1559692026802_2824_m_000047_2, Status : FAILED Error: Found interface org.apache.hadoop.mapreduce.Counter, but class was expected 19/06/19 11:16:49 INFO mapreduce.Job: Task Id : attempt_1559692026802_2824_m_000011_2, Status : FAILED Error: Found interface org.apache.hadoop.mapreduce.Counter, but class was expected 19/06/19 11:16:49 INFO mapreduce.Job: Task Id : attempt_1559692026802_2824_m_000034_2, Status : FAILED Error: Found interface org.apache.hadoop.mapreduce.Counter, but class was expected
위와 같은 에러로 인해 map작업이 계속해서 실패하며 다음과 같은 에러를 내며 죽어버린다.
Exception in thread "main" java.lang.NoSuchMethodError: org.apache.hadoop.mapreduce.Counters.getGroup(Ljava/lang/String;)Lorg/apache/hadoop/mapreduce/CounterGroup;
문제의 원인은 하둡 MR작업 중 Counter를 사용하는데 해당 라이브러리를 잘못 가져다 써서 문제가 발생한 것이였다.
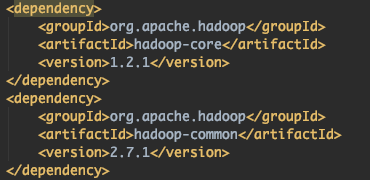
maven pom.xml
위와 같은 hadoop-core, hadoop-common 버전의 라이브러리를 사용해 작업을 했었다. 하지만 실제 하둡 MR을 구동하는 환경은 CDH 5.11.1에 설치된 하둡 패키지를 사용하고 있었기에 Counter메소드를 찾지 못해 NoSuchMethodError를 뱉는 것이었다.
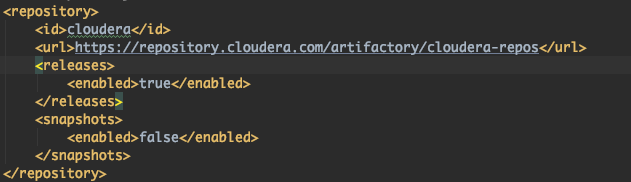
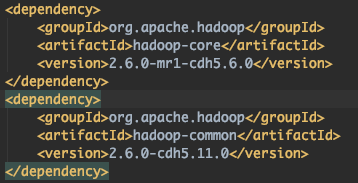
따라서 pom.xml에 repository와 depency 수정으로 해결하였다.
cloudera repository추가
cdh5.11.1에서 동작하도록 수정해주었다.
끝~~~~신기한건 똑같은 기능을 spark, mr둘다 만들어서 테스트해보았는데 단순히 데이터 읽어가면서 filterling하고 간단한 통계자료 뽑고하는 로직만 있어서 그런지 하둡MR이 훨씬 빨랐다는거....
When performing a shuffle my Spark job fails and says "no space left on device", but when I rundf -hit says I have free space left! Why does this happen, and how can I fix it?
Answers 1:
By defaultSparkuses the/tmpdirectory to store intermediate data. If you actually do have space left onsome device-- you can alter this by creating the fileSPARK_HOME/conf/spark-defaults.confand adding the line. HereSPARK_HOMEis wherever you root directory for the spark install is.
This is because Spark create some temp shuffle files under /tmp directory of you local system.You can avoid this issue by setting below properties in your spark conf files.
뭐 스파크 작업중 중간 과정에서 셔플링 데이터가 쌓이는데 해당 공간이 부족해서 그렇다며 스파크 디렉토리 데이터를 수정해주면 된다는~!
하지만 난 그냥 뭔가 spark-submit시 설정만 변경하기로 하고 설정을 다시 봤더니 executor-cores와 num-executor를 설정해주지 않은 걸 보고 default로 잡혀서 너무 작게 잡혀서 그런가 하고 추가로 넣어서 다시 spark-submit결과 정상동작하였다.